





I. De quoi s'agit-il ?▲
L'objectif de ce petit article est de vous présenter, à vous les « Spring addict », cette nouveauté de la version 2.0 de Spring que sont les namespaces. Je resterai malgré tout modeste, car tout ce que je raconte ici est le fruit de mes recherches sur le sujet alors que la documentation officielle n'est pas encore sortie. Vous trouverez en fin de document le lien vers l'article qui m'a fourni les premières pistes (en anglais).
Bon, les namespaces c'est quoi en quelques mots ?
Eh bien c'est un truc qui va faire que vos fichiers de configuration Spring seront beaucoup plus concis et lisibles. C'est aussi un truc qui va faire que les rédacteurs de fichier de configuration Spring seront aidés dans leur saisie et qu'ils seront plus heureux. Par contre, pour vous qui allez offrir cette facilité, c'est pas mal de boulot.
Autre point, ne vous découragez pas en lisant cet article, je sais que ce n'est pas le genre d'article qu'on lit en sirotant un bon cocktail sur une terrasse, mais une fois que vous saurez faire fonctionner les namespaces, vous les adorerez, enfin j'espère. Sinon, faites une pause entre chaque paragraphe, mais ce n’est pas grave, comme dirait monsieur KissCool.
II. Ça donne quoi alors ?▲
Dans l'exemple que je vais prendre par la suite, je vais utiliser Spring pour un usage peut être peu classique, c'est-à-dire que je vais me servir du fichier de configuration XML Spring comme une sorte de base de données. Je vais donc y déclarer des « beans » qui seront plutôt des objets persistants plutôt que des DAO ou autres EJB wrappers comme on le fait en général. Mais bon, l'essentiel est que vous compreniez la philosophie de la chose.
Donc mes objets sont en fait un objet « activité » qui possède un nom et des « livrables » en entrée/sortie.
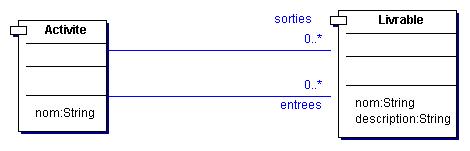
applicationContext.xml
<beans>
<bean id="act1" class="com.mycomp.Activite">
<property name="nom" value="Activite numéro 1"/>
<property name="entrees">
<list>
<bean ref="liv1"/>
</list>
</property>
<property name="sorties">
<list>
<bean ref="liv1"/>
<bean ref="liv2"/>
</list>
</property>
</bean>
<bean id="liv1" class="com.mycomp.Livrable">
<property name="nom" value="Mon livrable 1"/>
<property name="description" value="C'est un joli livrable"/>
</bean>
<bean id="liv2" class="com.mycomp.Livrable">
<property name="nom" value="Mon livrable 2"/>
<property name="description">
<value>
<![CDATA[Lui aussi il <b>est beau</b>]]>
</value>
</property>
</bean>
</beans>Avec un namespace approprié, voici ce que cela peut donner :
applicationContext.xml
<beans ...>
<m:activite id="act1" nom="Activite numéro 1">
<m:entrees>
<m:livrable ref="liv1"/>
<m:entrees>
<m:sorties>
<m:livrable ref="liv1"/>
<m:livrable ref="liv2"/>
<m:sorties>
</m:activite>
<m:livrable id="liv1" nom="Mon livrable 1" description="C'est un joli livrable"/>
<m:livrable id="liv2" nom="Mon livrable 2">
<m:description>
<![CDATA[Lui aussi il <b>est beau</b>]]>
</m:description>
</m:livrable>
</beans>Rapidement, on voit quoi ?
- Le fichier est plus concis, dans l'exemple on passe de 28 lignes à 18 lignes.
- On comprend mieux ce que l'on définit dans le fichier. En effet, au lieu d'utiliser les termes Spring génériques comme 'bean' ou 'class' ou 'property', on utilise nos propres termes (les tags provenant du XML schéma) que l'on a choisis pour être représentatifs des éléments que l'on déclare dans le fichier. Nos propres tags XML deviennent finalement notre langage 'propriétaire'.
- Le fichier ne contient plus d'attribut class= « … ». C'est a priori mieux pour celui qui tape le fichier, car on a souvent des noms à rallonge pour les classes.
- Enfin, on ne le voit pas dans l'exemple, mais on peut mixer dans un même fichier, des déclarations classiques et des déclarations utilisant plusieurs namespaces.
Finalement, pour ceux qui connaissent les pages JSP avec les taglibs, on a les mêmes avantages. On va voir que comme pour les taglibs JSP, il va falloir écrire du code Java, avec une petite différence, c'est que Spring va encore une fois nous aider et faire une partie du travail à notre place.
Ah ! Spring, quand tu nous tiens… !
III. Une vision générale▲
Voyons maintenant les éléments qu'il va falloir créer pour réaliser cette prouesse. Il nous faut donc :
- un schéma XML qui va définir notre propre syntaxe, la structure de nos objets et les relations qu'ils peuvent avoir, les plages de valeur autorisées pour les attributs… ;
- un ensemble de classes qui vont s'appuyer sur le framework Spring et dont le rôle va être de prendre en charge le « parsing » des tags XML que l'on aura défini ;
- des fichiers de configuration qui vont expliquer à Spring quelle est la classe Java (une de celles mentionnées ci-dessus) qui va prendre en charge le « parsing » des nouveaux tags ;
- modifier l'entête des fichiers de configuration Spring pour déclarer l'usage de notre schéma XML et donc nous permettre d'utiliser nos tags dans ces fichiers.
Il est à noter que l'utilisation d'un schéma XML pour la définition de « beans » dans le fichier de configuration Spring permet, au travers de l'usage d'un éditeur évolué (ben oui pas avec notepad ou vi !), de vérifier que les contraintes imposées par le schéma sont respectées (ce qui sera d'ailleurs aussi fait au chargement du fichier lors du lancement de votre application).
Dans le schéma qui définit votre nouveau langage de déclaration de « beans », vous pourrez donc définir des propriétés obligatoires ou optionnelles, définir des plages de valeurs pour une propriété, définir le nombre maximum d'occurrences d'une propriété, bref, tout ce qui vous permet de faire les schémas XML (et donc tout cela vérifié par des éditeurs comme XMLSpy ou Eclipse WT).
IV. Construction pas à pas▲
Bon allez, maintenant c'est parti, on ne rigole plus, on enlève les moufles et on plonge dans le vif du sujet, 1 2 3 GO !
IV-A. Étape 1 : construire le schéma XML▲
Tout d'abord, voyons le schéma dans son ensemble et examinons chaque définition ensuite :
<?xml version="1.0" encoding="UTF-8"?>
<xsd:schema xmlns="http://www.mycomp.com/schema/devcom" xmlns:xsd="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.mycomp.com/schema/devcom"
elementFormDefault="qualified" attributeFormDefault="unqualified">
<xsd:complexType name="descriptionType">
<xsd:simpleContent>
<xsd:extension base="xsd:string"/>
</xsd:simpleContent>
</xsd:complexType>
<xsd:complexType name="beanRefType">
<xsd:attribute name="ref" type="xsd:string" use="required"/>
</xsd:complexType>
<xsd:complexType name="livrableListType">
<xsd:sequence>
<xsd:element name="livrable" type="beanRefType" minOccurs="1" maxOccurs="unbounded"/>
</xsd:sequence>
</xsd:complexType>
<xsd:element name="livrable">
<xsd:complexType>
<xsd:sequence>
<xsd:element name="description" type="descriptionType" minOccurs="0" maxOccurs="1"/>
</xsd:sequence>
<xsd:attribute name="id" type="xsd:ID" use="required"/>
<xsd:attribute name="nom" type="xsd:string" use="required"/>
<xsd:attribute name="description" type="xsd:string" use="optional"/>
</xsd:complexType>
</xsd:element>
<xsd:element name="activite">
<xsd:complexType>
<xsd:sequence>
<xsd:element name="entrees" type="livrableListType" minOccurs="0" maxOccurs="1"/>
<xsd:element name="sorties" type="livrableListType" minOccurs="0" maxOccurs="1"/>
</xsd:sequence>
<xsd:attribute name="id" type="xsd:ID" use="required"/>
<xsd:attribute name="nom" type="xsd:string" use="required"/>
</xsd:complexType>
</xsd:element>
</xsd:schema>La définition des éléments correspondant aux objets est réalisée au travers des deux déclarations suivantes :
<xsd:element name="livrable">
<xsd:complexType>
...
</xsd:complexType>
</xsd:element>
<xsd:element name="activite">
<xsd:complexType>
...
</xsd:complexType>
</xsd:element>Notez que ces éléments déclarent à la fois des sous-éléments et des attributs. Nous allons voir par la suite que Spring se charge d'exploiter les attributs, mais l'exploitation des sous-éléments est à votre charge.
Les éléments du début du fichier genre <xsd:complexType …> permettent de définir des types de base utilisés ensuite dans la déclaration de nos éléments.
Au fait, le namespace c'est le truc http://www.mycomp.com/schema/devcom, on en reparle par la suite.
IV-B. Étape 2 : créer un « NamespaceHandler »▲
Bon, maintenant il va falloir dire à Spring le type d'objet à créer lorsqu'il va rencontrer les tags <m:activite> et <m:livrable>. Pour cela, nous devons écrire une classe, un « NamespaceHandler ». Cette classe est en fait le représentant de notre espace de nom et est chargée de déclarer les classes qui vont, elles, faire l'association entre un tag et un « bean » à instancier.
DevcomNamespaceHandler.java
package com.mycomp.devcom.config;
import org.springframework.beans.factory.xml.NamespaceHandlerSupport;
public class DevcomNamespaceHandler extends NamespaceHandlerSupport {
public DevcomNamespaceHandler() {
// Enregistrer les différents parsers si dessous
registerBeanDefinitionParser("activite", new ActiviteBeanDefinitionParser());
registerBeanDefinitionParser("livrable", new LivrableBeanDefinitionParser());
}
}Dans notre cas, on a créé deux classes « parseuses » de bean, ActiviteBeanDefinitionParser et LivrableBeanDefinitionParser.
IV-C. Étape 3 : créer un « BeanDefinitionParser »▲
Prenons d'abord l'exemple de la classe LivrableBeanDefinitionParser. Cette classe hérite d'une classe Spring , AbstractSimpleBeanDefinitionParser.
LivrableBeanDefinitionParser.java
import org.w3c.dom.Element;
import com.mycomp.devcom.Livrable;
public class LivrableBeanDefinitionParser extends
AbstractSimpleBeanDefinitionParser {
private static String TAG_DESCRIPTION = "m:description";
private static String PROP_DESCRIPTION = "description";
protected Class getBeanClass(Element element) {
return Livrable.class;
}
protected void postProcess(BeanDefinitionBuilder definitionBuilder,
Element element) {
super.postProcess(definitionBuilder, element);
// Récupération, éventuellement de la description en tant que sous-élément
List l = DomUtils.getChildElementsByTagName(element, TAG_DESCRIPTION);
if (l.size() == 1) {
Element e =(Element)l.get(0);
// Ajout de la propriété "description" avec la valeur texte du sous-élément
definitionBuilder.getBeanDefinition().getPropertyValues().addProperty(PROP_DESCRIPTION,DomUtils.getTextValue(e));
}
}
}La méthode getBeanClass doit renvoyer la classe du bean que vous voulez instancier lorsque Spring rencontre le tag que vous avez associé au « BeanDefinitionParser » :
méthode getBeanClass
protected Class getBeanClass(Element element) {
return Livrable.class;
}À ce stade, cela peut être la seule chose à faire au niveau de la classe « parseuse » de bean. En effet, les attributs XML du tag m:livrable, sont automatiquement exploités par Spring comme étant des attributs d'un JavaBean. L'affectation des valeurs de ces attributs pour une instance de Livrable va donc se faire comme si vous définissiez un tag <property name=« … » value=« … »/> classique.
Dans notre cas, nous acceptons un tag m:livrable avec un sous-élément m:description, il nous faut donc définir la méthode postProcess pour nous-mêmes gérer ces sous-éléments qui ne sont pas pris en charge par Spring. Remarquez que si la description est saisie comme un attribut, la propriété description du bean sera positionnée par Spring automatiquement.
La méthode postProcess récupère donc le sous-élément de l'élément courant (c'est-à-dire notre tag m:livrable) portant le nom m:description. Si ce tag est trouvé, on ajoute sa valeur au builder en cours de construction par Spring : definitionBuilder.getBeanDefinition(). Le « Builder » (du pattern… Builder évidemment) correspond à la définition de la classe de notre bean en cours de construction par Spring. On lui dit donc ici qu'une propriété de nom « description » a été définie dans le fichier XML.
Regardons maintenant le cas du tag m:activite. Ce tag accepte deux « sous-listes » (entrées et sorties), chaque élément de la liste est une référence à un livrable existant. Nous allons donc voir comment ajouter une liste de références vers d'autres beans dans le « builder » en cours de construction.
Pour cela, bien entendu, nous redéfinissons la méthode postProcess de notre grande « parseuse » de tag m:activite.
ActiviteBeanDefinitionParser.java
import org.w3c.dom.Element;
import com.mycomp.devcom.Activite;
public class ActiviteBeanDefinitionParser extends
AbstractSimpleBeanDefinitionParser {
private static String TAG_ENTREES = "m:entrees";
private static String PROP_ENTREES = "entrees";
private static String TAG_SORTIES = "m:sorties";
private static String PROP_SORTIES = "sorties";
private static String TAG_LIVRABLE = "m:livrable";
protected Class getBeanClass(Element element) {
return Activite.class;
}
protected void postProcess(BeanDefinitionBuilder definitionBuilder,
Element element) {
super.postProcess(definitionBuilder, element);
BeanDefinitionParserUtil.declareListRef(element, PROP_ENTREES,
TAG_ENTREES, TAG_LIVRABLE, definitionBuilder
.getBeanDefinition());
BeanDefinitionParserUtil.declareListRef(element, PROP_SORTIES,
TAG_SORTIES, TAG_LIVRABLE, definitionBuilder
.getBeanDefinition());
}
}Pour faciliter l'écriture de mes « parseuses », j'ai écrit une classe BeanDefinitionParserUtil qui sait prendre en charge, de manière relativement générique un certain nombre de situations pouvant être rencontrées au niveau de sous-éléments d'une définition d'un bean. Je vous livre donc une portion de cette classe, la portion définissant la méthode declareListRef.
méthode declareListRef de la classe BeanDefinitionParserUtil
public static void declareListRef(Element element, String property,
String tagListName, String tagName,
AbstractBeanDefinition definition) {
List l = DomUtils.getChildElementsByTagName(element, tagListName);
if (l.size() == 1) {
Element e = (Element) l.get(0);
List elts = DomUtils.getChildElementsByTagName(e, tagName);
ManagedList refs = new ManagedList();
RuntimeBeanReference ref;
for (int i = 0; i < elts.size(); i++) {
e = (Element) elts.get(i);
ref = new RuntimeBeanReference(e.getAttribute("ref"));
refs.add(ref);
}
definition.getPropertyValues().addPropertyValue(property, refs);
}
}La ligne : List l = DomUtils.getChildElementsByTagName(element, tagListName); récupère comme dans le code précédent le tag juste en dessous de l'élément courant. Dans notre cas, cela correspond au tag m:entrees (puis au tag m:sorties).
Dans le « if » qui suit, on récupère les sous-éléments du niveau encore en dessous, c'est-à-dire les éléments de la liste. Pour chacun des éléments de la liste, on demande l'attribut « ref » (ça, c'est le truc en dur que j'ai défini de la même manière que Spring utilise l'attribut ref pour les références) et on crée un « RuntimeBeanReference » avec cette référence, chaque RuntimeBeanReference est ajoutée à la « ManagedList » que nous avons créée avant d'itérer. Enfin, la ManagedList est ajoutée au « Builder » pour dire qu'il y a été défini une propriété de type « liste de références de beans ».
IV-D. Étape 4 : déclarer le « NamespaceHandler » et le schéma XML▲
Bon , on a fait le plus gros. Maintenant, il reste à faire le lien entre tout ça pour cela, Spring demande à ce que l'on crée deux fichiers : spring.handlers et spring.schemas.
spring.schemas (association namespace - fichier .xsd):
http\://www.mycomp.com/schema/devcom=mycomp.xsd
spring.handlers (association namespace - tag handler) :
http\://www.mycomp.com/schema/devcom=com.mycomp.devcom.config.DevcomNamespaceHandlerIV-E. Étape 5 : packager le tout▲
Pour packager le tout, il suffit maintenant de créer un fichier JAR avec les .class de votre « tag handler », de vos « parseuses » et les deux fichiers précédents, spring.schemas et spring.handlers, dans le répertoire META-INF du JAR.
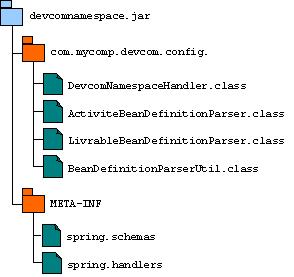
IV-F. Étape 6 : créer le fichier de configuration qui utilise nos tags▲
Tout est dans le sac, vous pouvez utiliser votre nouvelle bibliothèque de tags :
applicationContext.xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:m="http://www.mycomp.com/schema/devcom"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.mycomp.com/schema/devcom mycomp.xsd">
<m:activite id="act1" nom="Activite numéro 1">
<m:entrees>
<m:livrable ref="liv1"/>
<m:entrees>
<m:sorties>
<m:livrable ref="liv1"/>
<m:livrable ref="liv2"/>
<m:sorties>
</m:activite>
<m:livrable id="liv1" nom="Mon livrable 1" description="C'est un joli livrable"/>
<m:livrable id="liv2" nom="Mon livrable 2">
<m:description>
<![CDATA[Lui aussi il <b>est beau</b>]]>
</m:description>
</m:livrable>
</beans>Remarque : le fichier mycomp.xsd doit être accessible via le classpath.
Voilà, c'est terminé, pour l'étape 7, si vous n'êtes pas en train de dormir, je vous laisse le choix…
Merci à Jon pour ce premier petit article sur le sujet qui m'a permis de démarrer.
Et merci à vous d'avoir tenu jusqu'ici.